Vamos a dividir el estudio en 3 partes:
- OPERACIÓN (esta misma página)
- ATRIBUTOS y POLÍTICAS
- POLÍTICAS DE ENRUTAMIENTO
AUTENTICACIÓN
Podemos configurar autenticación para las sesiones BGP con MD5. Por defecto esta deshabilitada.

vMX-1
bgp {
authentication-key "$9$PTF6p0IreW9AeWLxwsP5Q"; ## SECRET-DATA
group iBGP {
type internal;
local-address 192.168.0.1;
authentication-key "$9$y.0eMLdb2GDkxNDk.P3nylK"; ## SECRET-DATA
neighbor 192.168.0.2;
neighbor 192.168.0.3;
}
group eBGP {
type external;
peer-as 65502;
neighbor 172.24.1.1 {
authentication-key "$9$1ciESl8X-24ZKM4ZUjPf1Rh"; ## SECRET-DATA
}
}
}
Nota: como vemos se puede configurar la autenticación a nivel global, a nivel de grupo y a nivel de peer.
Hay otra alternativa a la hora de autenticar. Juniper le llama "Hitless Key Rollover" y nos permite elegir entre varias claves para formar la sesión:
vMX-1
security {
authentication-key-chains {
key-chain eBGP {
key 1 {
secret "$9$-bbY4UjqQF/aZF/CtIR-Vw"; ## SECRET-DATA
start-time "2019-8-27.12:00:00 +0000";
}
key 2 {
secret "$9$j5km5n/tIEyQFEylKx7jHq"; ## SECRET-DATA
start-time "2019-8-27.00:00:00 +0000";
}
}
}
}
group iBGP {
type internal;
local-address 192.168.0.1;
authentication-key-chain eBGP;
neighbor 192.168.0.2;
neighbor 192.168.0.3;
}
Primero creamos bajo "security" la cadena de claves y luego lo asociamos al peer. Podemos establecer la autenticación tanto para internos como para externos. Se pueden crear hasta 64 "keys". Cada 12 horas usará una clave diferente.
Bgp almacena las rutas en 3 diferentes tablas conocidas como RIB (routing information bases) y las usa como base de datos:
- Adjency-RIB-IN: almacena todas las rutas recibidas de cada peer.
- RIB-LOCAL: contiene las rutas que usa para enviar tráfico
- Adjency-RIB-OUT: contiene todas las rutas propagadas a cada peer.
El protocolo BGP solo pasa las rutas ACTIVAS de las tala de rutas a la Adjency-RIB-OUT. De hecho, solo pasa la mejor ruta activa para cada destino en la RIB-LOCAL y la Adjency-RIB-OUT.
Hay veces que la mejor ruta no se propaga por alguna regla de la tabla de rutas local. Por ejemplo, si el equipo conoce una misma ruta tanto por IS-IS como por BGP, la ruta de IS-IS será la que esté activa debido a su "más bajo preference". BGP no la propagará al no estar activa para él. Si queremos evitar este comportamiento y que mande la mejor ruta aunque no esté activa, podemos usar el comando:
- advertise-inactive
REGLAS DE PROPOGACIÓN DE RUTAS EN BGP
Por defecto, BGP solo propaga rutas que estén activas.
Las reglas por defecto son:
- IBGP propaga rutas recibidas de un EBGP a otros IBGPs.
- EBGP propaga rutas recibidas de IBGPs o EBGPs a otros EBGPs
- IBGP no propaga rutas recibidas de IBGPs a otros IBGPs
Estas reglas se establecen para evitar bucles de enrutamiento.
Para la estabilidad del enrutamiento, todos los iBGP de un AS deben formar vecindad entre ellos, es de cir, todos tienen una sesión iBGP con todos los demás. Es lo que se denomina "full-mesh". Más tarde veremos que podemos hacer Confederaciones y Router Reflector para evitar tener que configurar full-mesh.
Cuando se reciben las rutas de un peer bgp, estas se instalan en la tabla RIB-LOCAL y podemos verlas con el comando "show route protocol bgp". Esto no siempre se cumple y las causas pueden ser:
- La ruta es una "Martian Route". (show route martians)
- Hay una política de "import" que filtra esa ruta para que no se instale
- El "next-hop" para llegar a esa ruta no lo resuelve el equipo. Si el router no puede resolver, no llega al next-hop que viene en la ruta y, por lo tanto, no la instala.
En Junos podemos usar una política para asignarle un "next-hop" específico dependiendo de la ruta y la aplicaremos como una "export" en las sesiones iBGP.
Otra opción es configurar una interface en "passive" en el protocolo IGP que tengamos montado. De esta manera no se montarían las sesiones contra esa interface pero se enviarían todas las rutas conocidas por el protocolo IGP, que normalmente suelen ser OSPF o IS-IS.
MULTIPATH EN BGP
Cuando configuramos multipath en BGP, el algoritmo ignora tanto el Router D como el Peer ID. Cunado recibe todas las rutas para llegar l adestino, este instala todas en la tabla de rutas local. Todas son mostradas pero solo un de ellas está marcada como activa. Esta ruta es la misma que sería seleccionada si no estuviera configurada la opción multipath. Además, el "next-hop" de estas rutas no activas también aparece listado como válidos para la ruta activa. Esto es lo que permite a Junos usar la opción por defect de "load-balancing", es decir, balanceo de carga.
Junos también usa la "extended community" de ancho de banda del enlace (link bandwidth) para balancear tráfico a través de enlaces que no tienen el mismo ancho de banda. El algoritmo envía proporcionalmente la carga de tráfico.
Multipath hace que el router remoto tenga la misma copia de las rutas que el emisor, ya sea un iBGP o eBGP.
 |
| Topología |
 |
| show route protocol bgp |
Configuradas las sesiones BGP en la topología, vMX-1 nos presenta una tabla de rutas donde aparecen las dos redes LAN del As 100. Vemos que sabe llegar a las dos rutas por ambas interfaces, pero es solo a través de la ge-0/0/1.0, es decir, a través de vMX-3, la ruta principal. Esto se ve porque tiene un asterisco. las otras no están marcadas como activas.
Ahora confguramos "multipath" en vMX-1:
- set protocols bgp group EBGP multipath
 |
| show route protocol bgp |
Ahora tiene 2 "next-hop" por cada ruta y, por defecto, Junos hará balanceo de carga. Cada ruta tiene un solo "next-hop" seleccionado y este es el que se instala en la tabla de envíos:

Según vaya aumentando la tabla de rutas, se irá distribuyendo los envíos.
- show route forwarding-table

Según vaya aumentando la tabla de rutas, se irá distribuyendo los envíos.
VECINDAD MULTIHOP
Por defecto, las conexiones eBGP usan el siguiente salto físico para montar las sesiones, es decir, la dirección ip de la tarjeta de red. Pero podemos montar las sesiones eBGP también sobre direcciones ip lógicas, es decir, loopbacks. Esto nos puede proporcionar ventajas como en el caso de tener múltiples conexiones físiscas entre dos routers. Si un enlace falla, la sesión eBGP no se cae proque se llega a la loopback del vecino eBGP a través del otro u otros enlaces.
Tenemos que configurar 3 partes:
- Local-address: la dirección ip de la loopback
- Multihop: para decirle que no apunte a la direcciópn ip física. Se pueden especificar el número de saltos (TTL).
- Conectividad: cada uno de ellos tiene que saber llegar a la dirección ip de la loopback del otro

root@vMX-1> show configuration | find routing-options
routing-options {
static {
route 172.16.0.2/32 next-hop [ 10.0.12.2 10.0.120.2 ];
}
autonomous-system 50;
}
protocols {
bgp {
group EBGP {
type external;
local-address 192.168.0.1;
neighbor 172.16.0.2 {
multihop {
ttl 1;
}
peer-as 100;
}
}
}
}
root@vMX-2> show configuration | find routing-options
routing-options {
static {
route 192.168.0.1/32 next-hop [ 10.0.12.1 10.0.120.1 ];
}
autonomous-system 100;
}
protocols {
bgp {
group EBGP {
type external;
local-address 172.16.0.2;
neighbor 192.168.0.1 {
multihop {
ttl 1;
}
peer-as 50;
}
}
}
}
 |
| show bgp neighbor |
ACEPTAR UN "NEXT-HOP" REMOTO
En Junos, si el "next-hop" de una ruta recibida desde un vecino eBGP que está a un solo salto no pertenece a una red compartida entre ellos, esta ruta es descartada. Normalmente configuraríamos este peer como "multihop". Cuando configuramos una sesión multihop, todos los "next-hop" de las rutas aprendidas del vecino eBGP son etiquetadas como "Indirect" incluso si comparten una red común. Esto rompe la función "multipath" entre las rutas que son resueltas recursivamente (preguntando a la tabla de rutas cómo llegar) y las que tienen incluido el "next-hop" en la ruta.
Si configuramos "accept-remote-nexthop" permite que esos "next-hop" se instalen como "Direct" y se restaura la función multipath. Si lo configuramos, tendremos que configurar también una política de IMPORT que especifique esa dirección del "next-hop".
También podemos usar esta opción para forzar a peer BGP con IPv4 para que acepte rutas que tengan un "next-hop" de IPv6.
Nota: no se puede configurar multihop y multipath para el mismo peer eBGP.
MULTIPLE NEXT HOPS
Dentro del context BGP, las opciones "multihop"y "multipath" pueden instalar rutas en la tala con múltiples "next hops" pero si miramos en la tabla de envíos solo hay seleccionado uno de ellos (forwarding-table).
Este comportamiento por defecto se puede modificar con un política de routing. La política debe contener la acción y aplicarla como políitca de "export" en la forwarding table, es decir, debajo de "routing-options"
- then load-balance per-packet
Si miramos la tabla de rutas nos encontraremos que tienen seleccionado únicamente un salto, pero si vamos a la tabla de envíos veremos que ahora son dos los destinos seleccionados como válidos.
El tráfico destinado para esta ruta ahora se decide en base a un "microflow hash algorithm", como dice Juniper, que usa la interface de entrada, la dirección ip de origen y la de destino. Estos valores que usa para decidir el envío se pueden modificar:
- forwarding-options hash-key family inet
Si además, especificamos "layer-4", incorporaría al hash el puerto de origen y el de destino
Vamos a configurar el ballanceo en el mismo ejemplo que teníamos con multipath:
|
| Topología |
Ahora configuramos en vMX-1 el balanceo. Primero cremao una política y después la aplicamos como export en la parte de "routing-options:
root@vMX-1# show | compare
[edit routing-options]
forwarding-table {
export BALANCEO;
}
[edit]
policy-options {
policy-statement BALANCEO {
then {
load-balance per-packet;
}
}
}
 |
| El tipo de envío lo etiqueta como "Unicast" |
OPCIONES DE CONFIGURACIÓN DEL PEER
|
| Topología |
- PASSIVE: si le configuramos el vecino el comando "passive" lo que haremos será cambiar el comportamiento por defecto que tiene BGP, es decir, activamente el router local manda un mensaje open. De esta manera no lo manda y espera que sea el peer remoto el que inicie la sesión.
root@vMX-1> show configuration protocols
bgp {
group EBGP {
type external;
peer-as 100;
multipath;
neighbor 172.16.0.2 {
passive;
}
neighbor 172.16.1.2 {
passive;
}
}
}
- ALLOW: también deja de mandar el mensaje OPEN. Sin embargo, con esta opción configuramos un rango de direcciones a las que permitimos que nos manden el mensaje OPEN sin tener la necesidad de configurar la dirección ip del peer remoto
root@vMX-1# run show configuration protocols
bgp {
group EBGP {
type external;
peer-as 100;
multipath;
allow 172.16.0.0/16;
}
}

Los vecinos a los que se les ha permitido montar la sesión contra nuestro equipo aparecen etiquetados como "un configured peers", pero vemos que las sesiones están levantadas
- PREFIX-LIMIT: no hay un límite por defecto para aceptar rutas. Podemos configurar un límite:
- maximum: configuramos la cantidad global de rutas recibidas
- teardown: configuramos un porcentaje a partir del cual el equipo genera un mensajes log y también la acción a ejecutar si se sobrepasa:
- idle-timeout: detiene la sesión hasta 40 horas. Se configura en minutos
- forever: detiene la sesión pero tendremos que reiniciarla manualmente
root@vMX-1# run show configuration protocols
bgp {
group EBGP {
type external;
family inet {
unicast {
prefix-limit {
maximum 500;
teardown 75 idle-timeout 15; - aquí podemos configurar "forever" en vez de 15 minutos
}
}
}
peer-as 100;
multipath;
allow 172.16.0.0/16;
}
}
- HOLD-TIME: cuando dos peers establecen una sesión negocian el hold time. En Junos, por defecto, es de 90 segundos (es 3 veces más que el keepalive, que en BGP es de 30 segundos). Podemos alterarlo para que vaya de entre 20 y 65535 segundos. Si el hold time entre dos peers es diferente, siemrpe negociara a la cantidad más baja.
root@vMX-1# run show configuration protocols
bgp {
group EBGP {
type external;
hold-time 50;
peer-as 100;
multipath;
allow 172.16.0.0/16;
}
}
- ADVERTISE-PEER-AS: por defecto Junos no propaga las rutas aprendidas de un EBGP a ese mismo EBGP o a cualquier peer que pertenezca al mismo AS que ese EBGP. Este comportamiento se puede modificar. Un ejemplo gráfico para usar este comando:
 |
| En este caso también podríamos usar el comando "as-override" |
GRACEFUL RESTART
Cunado un router soporta "graceful restart" puede reinicar su proceso de routing(rpd) sin causar un cambio de topología en la red. Cuando se establece la sesión BGP, los routers negocian la posibilidad de "graceful restart". Solo funciona si ambos equipos tienen la capacidad de habilitarlo.
Cuando el router reinicia el proceso de routing, los vecinos sigue enviándole tráfico. La pérdida de los mensajes de "keepalive" no hace que el vecino deje de propagar las rutas del equipo que está reiniciándose.
El equipo que se reinicia configura el "bit del restart" y el "bit de forwarding" dentro del mensaje OPEN. Esto hace que el vecino no ejecute el algoritmo de BGP y siga viendo como activo y normal la operación del equipo que se reinicia.
Una vez reiniciado la sesión se establece otra vez y se intercambian la información de rutas. Cuando la última ruta es enviada, se marca un "END-OF-RIB" para informar que el proceso está completado. Este "END-OF-RIB" es un simple mensaje de UPDATE vacío. Es a partir de ese momento cuando el equipo que recibe las rutas puede ejecutar el algoritmo de BGP para elegir el mejor camino. Se configura bajo "routing-options" y tenemos 3 opciones:
- set routing-options graceful-restart
- Disable: el router local no participa en el "Graceful Retsart"
- Restart-Time: el tiempo que transcurre para reestablecer la sesión. El rango va de 1 a 600 segundos
- Stale-Routes-Time: es el tiempo que las rutas del equipo que se reinicia siguen activas y no se declaran caídas.
LOCAL PREFERENCE (el único atributo que cuánto más alto, mejor)
Es el atributo de prioridad de Juniper. Se puede configurar para BGP a nivel global, de grupo o por peer. Todas las rutas propagadas heredarán esta valor, excepto aquellas a las que le configuramos y aplicamos una política para cambiar este valor, es decir, la configuración del local-preference se aplica antes de la polítca, por eso podemos cambiar este valor. Creo que me explicado bien, ¿no? :-)

Si miramos las rutas que le pasa vMX-2 a vMX-1 vemos que la ruta 192.168.0.0/24 la propaga con un local-preference de 100.
Ahora le configuramos a vMX-2 un local-preference diferente para que se lo propague a vMX-1:

AS PATH
Podemos modificar el AS PATH de una ruta con el comando "remote-private". De esta manera, un ISP puede modificar al AS PATH de las rutas que le mandan sus clientes desde un AS con numeración privada. Esta opción no se debe usar cunado tenemos Confederaciones de BGP (lo vemos después).

En este ejemplo vMX-1 hace de ISP y tiene dos clientes que exportan la loopback cada uno. Y después, vMX-1 se las pasa a vMX-4 que emula Internet.
Podemos ver que el AS PATH ES: 100 65002 y 100 65003.
Ahora le aplicamos el comando para que quite la información de los AS privados:
Si ahora nos vamos a vMX-1, este no debería recibir ahora en el AS PATH los número de los privados:
Otra manera de modificar el AS PATH es usando el LOCAL-AS. El uso frecuente del local-as es para ayudar a la migración de los nuevos clientes de un ISP a un nuevo AS.
El ejemplo para entenderlo es el siguiente usando la misma topología de antes pero sin haberle aplicado el remote-private enla configuración:
Podemos ver que el AS PATH ES: 100 65002 y 100 65003.
Ahora imaginemos que el AS 100, que es un ISP, se fusiona con otro ISP que tiene el AS 200.

Una vez montado los peers, vemos que el AS PATH ahora tiene al AS 200 en el camino:

La nueva empresa que tiene dos AS diferentes decide usar solo el AS 200 como su AS público.
Vamos a vMX-1 y configuramos:
Así se hace según Juniper. A mí no me oculta el AS 65002 o 65003. Os dejo un enlace oficial de Juniper donde dice que se configura así, pero por más que he insistido, a mí no me funciona. Si a alguno le sale, por favor, que nos lo aclare:Es el atributo de prioridad de Juniper. Se puede configurar para BGP a nivel global, de grupo o por peer. Todas las rutas propagadas heredarán esta valor, excepto aquellas a las que le configuramos y aplicamos una política para cambiar este valor, es decir, la configuración del local-preference se aplica antes de la polítca, por eso podemos cambiar este valor. Creo que me explicado bien, ¿no? :-)

Si miramos las rutas que le pasa vMX-2 a vMX-1 vemos que la ruta 192.168.0.0/24 la propaga con un local-preference de 100.
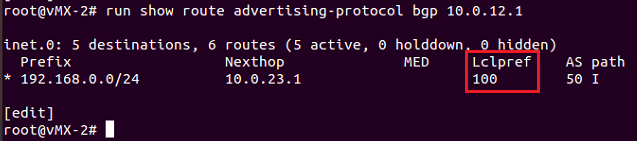 |
| show route advertising-protocol bgp 10.0.12.1 |
- set protocols groups IBGP local-preference 200

AS PATH
Podemos modificar el AS PATH de una ruta con el comando "remote-private". De esta manera, un ISP puede modificar al AS PATH de las rutas que le mandan sus clientes desde un AS con numeración privada. Esta opción no se debe usar cunado tenemos Confederaciones de BGP (lo vemos después).

En este ejemplo vMX-1 hace de ISP y tiene dos clientes que exportan la loopback cada uno. Y después, vMX-1 se las pasa a vMX-4 que emula Internet.
 |
| show route en vMX-4 |
Podemos ver que el AS PATH ES: 100 65002 y 100 65003.
Ahora le aplicamos el comando para que quite la información de los AS privados:
- set protocols bgp group EBGP-INTERNET remove-private
 |
| show route configuration protocols en vMX-1 |
Si ahora nos vamos a vMX-1, este no debería recibir ahora en el AS PATH los número de los privados:
 |
| show route en vMX-4 |
Otra manera de modificar el AS PATH es usando el LOCAL-AS. El uso frecuente del local-as es para ayudar a la migración de los nuevos clientes de un ISP a un nuevo AS.
El ejemplo para entenderlo es el siguiente usando la misma topología de antes pero sin haberle aplicado el remote-private enla configuración:
|
| show route en vMX-4 |
Podemos ver que el AS PATH ES: 100 65002 y 100 65003.
Ahora imaginemos que el AS 100, que es un ISP, se fusiona con otro ISP que tiene el AS 200.

Una vez montado los peers, vemos que el AS PATH ahora tiene al AS 200 en el camino:

La nueva empresa que tiene dos AS diferentes decide usar solo el AS 200 como su AS público.
Vamos a vMX-1 y configuramos:
- set protocols bgp group EBGP-AS-200 local-as 100 private
https://www.juniper.net/documentation/en_US/junos/topics/topic-map/bgp-local-as.html
MED y MÉTRICAS DE IGP
En junos podemos configurar MED para todas las rutas de un peer, un grupo o a nivel global:
- set protocols bgp metric-out X - le asigna el valor que le demos
- set protocols bgp metric-out igp - le asigna la métrica interna del IGP
- set protocols bgp metric-out minimum-igp - le asigna la métrica interna más baja posible del IGP
- set protocols bgp metric-out igp [X /-X] - le añade o resta el valor que le demos la métrica interna del IGP. Se usa conjuntamente con los dos anteriores
En Junos, la acción por defecto cuando recibe rutas que pertenecen al mismo AS es comparar los valores de MED para elegir. En un ejemplo se ve claro:
Imaginemos que nos llegan 3 rutas para el mismo destino:
- AS PATH: 65001 MED: 200 from EBGP
- AS PATH: 65005 MED: 150 from IBGP IGP cost: 10
- AS PATH: 65001 MED: 100 from IBGP IGP cost: 20
En este caso, nuestro equipo Junos comparará primero las MED del camino 1 y 3 ya que vienen del mismo AS. Como el camino 3 tiene mejor MED, elige este. Luego compara el camino 3 con el camino 2. Ambos se reciben de un IBGP, así que el coste del camino 2 es lo que marca la diferencia y, por lo tanto, será elegida esta ruta y será la que se marcará como activa en la tabla de rutas.
Tenemos un par de comandos para jugar con MED:
- set protocols bgp path-selection always-compare-med
Esto hace que se compare el MED de todas las rutas sin importar si vienen del mismo AS. Siempre elegirá la que tenga el MED más bajo sin importar el AS de procedencia. Si lo aplicamos al ejemplo anterior, sería el camino 3 el elegido.
Hay que tener mucho ciudado con este comando porque el MED es un valor que cada unos configura a su manera y para unos los valores de MED buenos puede ser una configuración de 50 y para otros de 5. Además, MED es opcional, es decir, no es obligatoria su configuración y cuando no se configura sale con un valor de 0.
El otro comando para jugar es:
- set protocols bgp path-selection cisco-non-deterministic
Cuando se configura, el equipo compara las rutas en el orden que han llegado sin tener en cuenta que haya múltiples rutas para llegar a un destino que provienen desde el mismo AS y puede incurrir en malas elecciones. Con el ejemplo anterior, el equipo comapraría el camino 3 que es el último que se ha recibido con el camino 2. El coste de IGP es más bajo en el camino 2, así que elegiría este. Luego compararía con el camino 1 y, como es un EBGp, se impone la regla de preferir EBGP antes que un IBGP, por lo que elegiría finalmente el camino 1 como ruta activa.
No hay comentarios:
Publicar un comentario